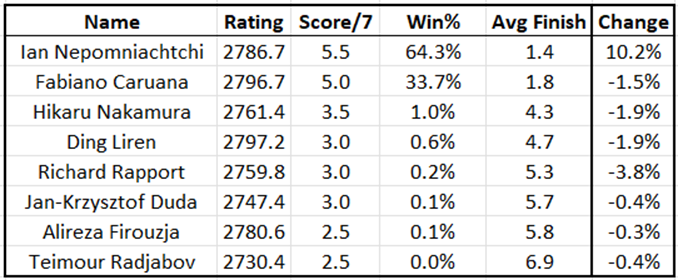
As the 2024 Candidates Tournament approaches, we have of course released our model’s Elo-driven predictions, and as always one of the core questions is are there any factors other than rating which are uniquely predictive, that the model is ignoring? Generally speaking, we assume that while commonly cited traits (age, experience, etc…) may have predictive value, they don’t tend to offer any new information that isn’t already captured in a player’s rating. However there is one particular question we do find fascinating for this event: given that Nepomniachtchi has won the Candidates in both of his prior attempts, is there any reason to think he might be uniquely good at this event, and thus that his chances of winning again are underrated by looking solely at his rating?
It is possible to look at how players did relative to their ratings in prior Candidates tournaments by comparing their performance ratings in the event to their initial published ratings, and seeing who over or under performed their ratings-based expectations. To specifically assess whether prior results predict future results (at this specific event and format) we could then see if people who overperformed before tend to do so again, or if over/under performance appears random. However performance rating (even in a 14 round event) is a highly variable measure so to really extract meaningful, statistically significant, conclusions would require lots of data. And we don’t have it. There have only been 48 total individual event performances to look at (6 events, from 2013 to 2022, with 8 players per event) in the current format.
So any attempt to analyze this question with such limited data is going to be “statistics” in the sense of when baseball broadcasters tell you a players batting average with runners on scoring position – on Tuesdays – than it will be “statistics” in the sense of the academic discipline. With that understanding, we’re going to do it anyway!
First of all, let’s talk about the raw data. We have compiled all 48 Candidates performances, in chronological order, with how the player did relative to their rating, their age (outside the scope of this analysis), and counted how many prior/future appearances they have in the data set.
Of the 48 data points, there are 11 with zero prior events *and* zero future events, which is to say players who only competed in this Candidates format once. These will not help us in any way, to see if past performance predicts future performance, so immediately we’re down to 37 potentially useful data points. This leaves us with 14 players that have competed more than once in the Candidates, with 7 of them having played twice, 5 of them having played three times, and 2 having had four shots.
There are three ways we can attempt to parse this data that we will explore here. We can look only at each player’s first two events, and see if people tend to do better, worse, or the same (again, relative to rating) the second time around. We can also look at how each player’s first event compares to *all* their events that come afterwards (1, 2, or 3), to see if a first appearance establishes a meaningful long-term basis for whether they are uniquely good or bad at this event. And finally, most fittingly for Nepo’s situation, we can look at each player’s *most recent* result and compare it to all of their prior events to see if there is any reason to think their final (so far) mark was predictable in a way based on earlier results.
Let’s start with first two. Here is a chart of each of the fourteen players’ first and second Candidates performances and their “try two delta”, or whether their relative performance was better or worse, and by how much, the second time around.

The average change is just 5 points, half the players improved on try two and half did worse. The five players whose first event was negative had positive second events three times and negative twice. The nine players who started out positive were positive again five times and negative four times. In other words, no matter how hard we squint, this looks almost entirely random. A player’s first Candidates appearance does *not* appear to predict their second result in any way. Good news for Alireza Firouzja and his fans, perhaps, but maybe not entirely relevant to Nepo’s situation as the main point here is that he caught our attention and inspired this article by winning twice in a row, not just because of his first overperformance.
Before moving on we want to make a note about Radjabov. The biggest “improvement” from event one to event two is also the sketchiest data point. There was almost a full decade between the two events, as he literally played the first and last event we’re considering. And that first event was the biggest underperformance out of the entire initial set of 48, so regression to the mean was hardly surprising. It’s not statistically sound to just declare something an outlier because you don’t like it, but since we’ve already accepted that this analysis is operating more on “feel” than pure statistical rigor, we have to note that this data point feels like an outlier, whether that’s truly justified or not. Moving forward we will do our next two analyses both including and excluding it, to see how much effect it has on possible conclusion.
So let’s now allow the third and fourth appearances (where they exist) to join the data set, and see if adding that data in allows each player’s first appearance to appear any more predictive. On this graph we have first appearance over/under performance on the x-axis, while averaging *all future* over/under performances and placing them on the y-axis.

We can see that while the trendline slopes very slightly upward, there is basically no correlation here. But ignore that dot in the top left (Radjabov) and the eye test suggests maybe there actually is something here. Since we’re just messing around with what we already know to be insufficient data, and we already know all conclusions come with a giant grain of salt, let’s go ahead and see how the graph looks without that point:

There’s nothing here I find convincing, but it is at least true that we’re starting to see a little bit of correlation after randomly throwing out the weird data point we don’t like with no real justification. It’s super random near the center, players whose first event was a relatively slight over or under performance don’t show us anything too interesting, but the biggest (non-Radjabov) underperformance was a player who underperformed again, and the three biggest first-event overperformances are players who overperformed their future events as well. Here’s the data, if you prefer that to a graph. I’m not convinced, but it’s getting vaguely interesting.

So what about looking from the end, instead of from the beginning? How predictable was each of these 14 players’ final (as of 2022) Candidates result (relative to their rating) based on the average of all their prior events? Once again, let us turn to the graphs. First the full data:

And once again, Radjabov just doesn’t fit the eye test, so let’s stop burying the lead and just skip to the chart that ignores him:

Suddenly we have significant correlation! Not significant amounts of data, it’s all still super sketchy to really claim any of this means anything… but it sure starts to seem like if we look at all of a player’s prior performances we can start to get some sense that if they are historically better or worse in their previous Candidates attempts than their rating indicates, maybe that actually does suggest they’ll do better or worse than their rating this time around too. Here’s the data table:

When you average multiple prior performances (where possible), most players don’t actually have a history of significantly over or under performing. From Levon (-27) to Fabi (+22) there are eight that didn’t really make a prediction about our final result. The two who entered significantly underperforming in the past each only had one prior event, so hard to draw much meaning from that either. But the bottom of the chart feels genuinely interesting. The four players with the best prior performances relative to rating (and two of them did have multiple events) all proceeded to overperform again.
Did we have to take a tiny amount of data, and massage it a lot to force a pattern to emerge? Yes. Is any of this statistically significant? No. Will we be adjusting our simulation model to account for anything we found here? Also no. But… before looking all of this over we really fully took for granted that it doesn’t make sense for a player to be uniquely good at the Candidates, in a way that isn’t just “being good at chess” and captured by their rating. Now, we feel a little bit less sure.
Looking just at players who have won the Candidates, Karjakin didn’t just overperform his rating when he won, he did so the other two times he played as well. Anand didn’t just overperform his rating when he won, he did so the other time he played as well. Nepo has just won twice, obviously dramatically overperforming his rating both times. Caruana has actually underperformed his rating two of the three times he didn’t win, but that includes 2022 when he was initially overperforming and had an apparent lock on second, but threw it away chasing first place, and also that is partially just the problem of being seeded 1st, 1st, and 3rd by rating in those three events, so having extra high expectations to live up. It’s a hilarious sidenote that the one time he won was actually the year he was seeded 5th. And speaking of high expectations, the year Carlsen won he actually underperformed his absurdly high rating. Here’s a final chart of *every* candidates performance from someone who has won the event.

Obviously, Magnus aside, they overperform when they win, but these players collectively have tended at least slightly towards overperformance across their non-victorious appearances as well. Perhaps it is at least slightly valid to think that a select few players are legitimately and uniquely strong at this specific event. We certainly wouldn’t conclude that Nepo’s prior average overperformance of 108 points means we should expect him to play like a 2866 (that is to say 2758 + 108) as his baseline expectation this time around. But if you look at all of this analysis and conclude that it’s fair based on past results to think Nepo should be simulated as if he’s, say, 2780ish instead of 2758, we can’t fault that conclusion.
What do you think? Does it feel like there’s something real here? Or do the tiny sample sizes tell you this is all rubbish? After reading all of this, what baseline rating would you assign Nepo for a simulation model of the 2024 event? His actual 2758, or something higher based on his prior results?